
Aktuelles
Neue Funktion in EXTRAKT: RPOS
Mit dieser Funktion wird die Position der sprachlichen Elemente (Einzelwörter und Syntagmen) in dem Anfragestring zurückgeliefert.
25.09.2024
100 Companies that Matter in Knowledge Management 2024
Und dazu gehört die Semantic Web Company ... und TEXTEX liefert die linguistic engine EXTRAKT dazu! Siehe: www.kmworld.com
Update deutsches Wörterbuch
Im November wird die neue Version des deutschen Wörterbuchs ausgeliefert. Es enthält nun alle Verbstamm-Formen zu allen Verben. Ein Verbstamm ist die Grundform eines Verbes, die in einem Kompositum verwendet wird. Etwa "vorzeige" zum Verb "vorzeigen", um etwa ein Kompositum wie Vorzeigesportler zu bilden. Es sind ca. 12.000 zusätzliche Wortformen.
28.10.2023
Linguistik und Filero
Filero ist nun standardmäßig mit EXTRAKT ausgestattet!
Filero verwaltet Dokumente, d. h. jede Art von Texten. Texte bestehen aus Sätzen und Wörtern. Wörter gehören zu einer bestimmten Sprache - sie bilden den Wortschatz.
FILERO speichert die Dokumente, damit sie nicht verloren gehen und man sie wieder finden kann. Dazu muss man die ID des Dokumentes oder seinen Namen oder ein anderes Merkmal wissen. Oder man sucht nach einem Begriff, der in dem gesuchten Dokument vorkommen muss.
Die Begriffe sind aber sprachlicher Natur - die Wörter - und deshalb sind die gesuchten Begriffe oft nicht identisch mit den Begriffen in den Dokumenten: der Suchbegriff kann in einer sprachlichen Variante im Text vorkommen und dadurch nicht identisch mit dem gesuchten Begriff sein. Ein triviales Beispiel ist das Wort "Haus", das in einem gesuchten Dokument als "Häuser" vorkommen kann. Es ist klar, dass Haus und Häuser denselben identischen Begriff "Haus" darstellen. Das liegt auf der Hand, doch ein Computersystem oder das Dokumentenmanagementsystem, mit dem man suchen will, stellt nicht automatisch die Verbindung zwischen den beiden Wortformen her.
Es sei denn, es handelt sich um FILERO, denn FILERO hat die linguistische Maschine EXTRAKT integriert. EXTRAKT führt die notwendigen Operationen durch, um derartige Beziehungen herstellen zu können. Hierbei handelt es sich nicht nur um die Abbildung von beliebigen Wortformen zueinander, sondern um komplexe Verfahren zur Feststellung der in einem Text vorliegenden Begriffe. Zusätzlich lassen sich mit Hilfe von EXTRAKT lautlich ähnliche Wörter/Namen finden (TRAPHO-Funktion); auch lassen sich die wichtigsten Sätze in einem Textabschnitt ermitteln (SUMUP-Funktion).
EXTRAKT basiert auf "menschlicher Intelligenz" und ist somit transparent hinsichtlich der Resultate bei einer Suche. Die Entwicklung dazu begann in den 1980er Jahren und wurde auch in verschiedenen internationalen Forschungsprojekten entwickelt, die von der Kommission der EU unterstützt wurden. Die grundliegende Idee stammt von Christian Fluhr, damals Professor beim Commissariat de l'énergie atomique (CEA Kommissariat für Atomenergie) in Saclay bei Paris.
18.11.2022
Wörter analysieren
Welche Varianten hat ein Wort?
Das kann man mit Lexxi überprüfen - in verschiedenen Sprachen.
Einfach auf www.lexxi.eu gehen und ein Wort eingeben. Und schon werden alle Formen angezeigt plus Synonyme und verwandte Wörter.
11.2.2022
DYM3 zum kostenlosen Test
DYM3 ermöglicht eine Namenssuche bei der man die genaue Schreibweise des Namens nicht kennt.
Wer weiß, wie die Hauptstadt Islands geschrieben wird, oder wie schreibt man richtig: Lybien oder Libyen?
In der Demo können die Ortsnamen von Deutschland, Österreich und der Schweiz durchsucht werden.
Eine E-Mail an stegentritt@textec.de reicht, um den Demonstrator zu erhalten!
Oder testen Sie DYM3 bei Weitkamper.de
3.5.2021
EXTRAKT WIndows Service
Neben der Server-Version von EXTRAKT steht nun auch ein Windows-Service zur Verfügung.
Dadurch wird die Einbindung und das Nutzen der EXTRAKT-Funktionen in Client-Anwendungen vereinfacht. Die Funktionen selbst sind mit denen der Server-Variante identisch.
Die Entwicklung der Service-Variante wurde in Kooperation mit unserem Partner LIB-IT DMS GmbH (www.lib-it.de) realisiert; sie kommt im Enterprise Information Management System FILERO standardmäßig zum Einsatz.
Das Server-Programm basiert auf dem Programmbeispiel „Sampleservice“ von Mohit Arora.
22.1.2021
Neue Sprachen für die phonetische Suche
Die phonetische Suche (TRAPHO) wurde ergänzt mit den Sprachen Griechisch, Arabisch und Türkisch.
Die isländische Version ist in Entwicklung.
Gleichzeitig wird ein isländisch-dänisches Wörterbuch aufgebaut.
21.7.2020
Semantic Web Company
Unser Partner in Wien, der unsere Linguistik im Verbund mit der PoolParty Suite einsetzt, wurde von KMWorld unter die 100 wichtigsten Firmen im Bereich Wissensmanagement gewählt!
Mehr dazu: bei PoolParty.
- 11.3.2019 -
Deutsch
Das deutsche Grundformen werden mit dem Datenbestand der deutschen Wikipedia abgeglichen; insbesondere Ortsnamen wurden hinzugefügt, aber auch einige wenige Substantive.
- 19.1.2019 -
NIEDERLÄNDISCH
Eine neue Version der Wörterbücher steht zur Verfügung. Insbesondere das Wörterbuch für Niederländisch wurde erweitert.
- 19.4.2018 -
Mehr deutsche Wörter
Das deutsche Wörterbuch ist wieder ein wenig angewachsen: nun sind es mehr als 3 Millionen Einträge.
Der Zuwachs besteht insbesondere aus technischen Begriffen, wie Clausthalit, Silizifikation oder Nesosilikat. Zu den Komposita gehören Formen wie martensitaushärtend, langbrennweitig oder Bendixmessgerät.
-10.12.2016-
Positionen
Will man im Analyse-Resultat die Positionierung des Lemmas im Originaltext so kann man dies durch einen zusätzlichen Parameter POS anfordern. Im Resultat erscheint dann ein Element, das die Werte der Anfangs- und Endposition enthält.
-07.06.2016-
Links
Um in Texten Links auf Internet-Seiten und Mail-Adressen zu erkennen, wurde eine neue linguistische Klasse eingeführt (LNK für Link), die in der INDEX2-Funktion genutzt wird.
Es können dadurch Verweise auf Internet-Seiten, etwa "www.textec.de" oder e-mail-Adressen erkannt und mit der Klasse LNK versehen werden.
Durch die Möglichkeit, die Resultate nach Wortklassen zu filtern, ist es auch möglich, aus Dokumenten lediglich diese Verweise herauszuziehen.
-03.09.2015-
Maskulin - Feminin
"Maskulin-Feminin" (Masculin-Féminin) ist ein Film von Jean-Luc Godard, in es um die Liebesbeziehungen junger Franzosen geht. Die Beziehungen zwischen den Geschechtern ist auch Gegenstand des neuen Maskulin-Feminin-Wörterbuchs von EXTRAKT.
Die Bezeichnungen für männliche Personen und Berufe werden den weiblichen Entsprechungen zugeordnet. So steht ein Minister in (grammatischer) Relation zur Ministerin, ein Graf zur Gräfin, ein Koch zur Köchin, ein Organist zur Organistin und ein Wissenschaftler zur Wissenschaftlerin - und umgekehrt.
Dadurch können von der maskulinen Form auch auf die femininen Pendants geschlossen werden und sie können bei der Suche auf vielfältige Weise genutzt werden.
Das Maskulin-Feminin-Wörterbuch enthält ca 160.000 Worteinträge und kann mit allen linguistischen Funktionen von EXTRAKT genutzt werden.
-16.08.2015-
LexiQuo /LeXXiNet
haben wir weiter entwickelt. Nun werden das Niederländische und das Portugiesische durch unsere Linguistik unterstützt.
Die sprachlichen Varianten der Suchwörter werden auf Wunsch in getrennten Fenstern angezeigt.
Dazu gehören die Synonyme (bedeutungsverwandte Begriffe), die Wortfamilien oder Ableitungen (formal verwandte Begriffe), die Übersetzungen in andere Sprachen (Deutsch, Englisch und Französisch) und lautlich ähnliche Begriffe. Letztere sind Wörter (vor allem Namen), die ähnlich ausgesprochen werden können als der/die Suchbegriff/e. Hierzu wird unser phonetischer Server TRAPHO eingesetzt.
-09.02.2015-
LexiQuo (LeXXiNet)
In die Meta-Suche mit der linguistischen Anreicherung durch EXTRAKT wurde die Suchmaschine
QWANT hinzugefügt.
QWANT führt einen eigenen Index, bewahrt die Anonymität der Suche und verfügt über eine neuartige Präsentation der Ergebnisse.
An Qwant ist unser Partner Pertimm beteiligt.
Standardmäßig werden nun die Resultate von BING angezeigt. Das liegt daran, dass BING es erlaubt, sie in einem eigenen "frame" anzuzeigen, so dass nicht ein neues Fensetr geöfnet werden muss. Das hat nun zur Folge, dass die Bing-Resultate stest sichtbar sind und alternative Resultate einer anderen Suchmaschine darüber geblendet werden.
-06.01.2015-
Wörterbücher 5.0
Die neue Wörterbuch-Version enthält Erweiterungen für die Sprachen Deutsch und Niederländisch.
- Das deutsche Wörterbuch enthält nun 2.366.000 Einträge, davon 437.000 Komposita-Lemmata.
- Das niederländische Wörterbuch enthält nun 132.000 Einträge, davon 12.000 Komposita-Lemmata.
An der Anreicherung des niederländischen Wörterbuchs wird weiter gearbeitet, so daß diese Komponente nicht nur für die DetectLanguage-Funktion, sondern auch für die INDEX und ANALYZE-Funktionen eingesetzt werden kann.
-21.11.2014-
Korfs Brille [ oder ein frühes SUMUP ]
Korf liest gerne schnell und viel;
Darum widert ihn das Spiel
all des zwölfmal unerbetnen
Ausgewalzten, Breitgetretnen.
Meistens ist in sechs bis acht
Wörtern völlig abgemacht,
und in ebensoviel Sätzen
läßt sich Bandwurmweisheit schwätzen.
Es erfindet drum sein Geist
etwas, was ihn dem entreißt:
Brillen, deren Energieen
ihm den Text - zusammenziehen!
Beispielsweise dies Gedicht
läse, so bebrillt, man - nicht!
Dreiunddreißig seinesgleichen
gäben erst - ein - - Fragezeichen!!
(Christan Morgenstern)
-24.6.2014-
UTF 8
UTF 8 ist fast zu einem Standard geworden für die Zeichencodierung. In EXTRAKT jedoch sind die Wörterbücher in dem Iso-8859-1 (Latin-1) gespeichert. Durch eine interne Umwandlungsfunktion kann ab Version 5.0 b03 EXTRAKT auch UTF 8 verstehen. Da in den Wörterbüchern nur ein bis zwei Byte lange Zeichen vorkommen werden nur diese Zeichen konvertiert.
-13.6.2014-
Linguistische Software
Sucht man mit dem Begriff "Linguistische Software" in Google, so erscheint TEXTEC an erster Stelle in der Trefferliste.
Google hat's also verstanden. Wohingegen der Veranstalter eines Info-Nachmittags zu dem Thema "Intelligente Sprachtechnologien aus dem Saarland" erst durch einen direkten Hinweis von TEXTEC von unseren linguistischen Produkten Kenntnis nahm (http://www.saar-is.de/innovation).
-23.4.2014-
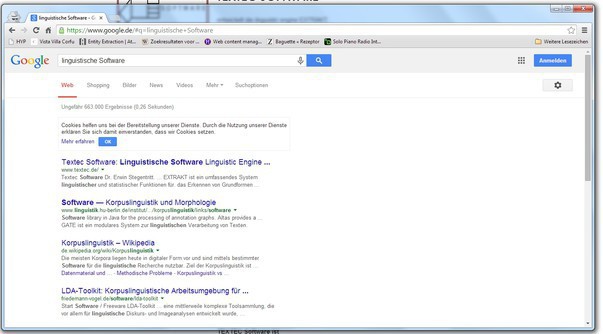 Suche mit "linguistische Software" in Google (25.4.2014)
Suche mit "linguistische Software" in Google (25.4.2014)
EXTRAKT und PoolParty
EXTRAKT wird in Verbindung mit der PoolParty Suite der Semantic Web Company eingesetzt. Die PoolParty dient dazu, semantische Zusammenhänge in Dokumenten zu entdecken und auszunutzen.
EXTRAKT hilft dabei, die Wort-Variationen in den Dokumenten auszugleichen und verbessert dadurch die semantische Suche.
-21.03.2014-
EXTRAKT & JAVA
Eine Neuprogrammierung von EXTRAKT hat begonnen. Die Grundfunktionen des Wörterbuchzugriffs, der Wörterbuchverwaltung, der Indexierung (mit Kompositazerlegung) und der Generierung sind fertiggestellt. Nach und nach werden die restlichen Funktionen folgen.
-11.03.2014-
Verfeinerung der Komposita-Zerlegung
Die automatische Zerlegung deutscher Komposita ist eine komplizierte Aufgabe, denn ein Kompositum enthält im Grunde eine ganze syntaktische Struktur. Der erste Schritt bei der Zerlegung ist die Bestimmung der einzelnen Komponenten. Dabei wird auf die Wörterbücher zurückgegriffen, die in EXTRAKT geladen sind. Hierbei sind besonders kurze Wörter und Abkürzungen besonders problematisch: einerseits sollen sie erkannt werden, andererseits sollen sie nicht bei der Zerlegung des Kompositums als Kandidat eines Konstituenten auftreten dürfen.
In der aktuellen Version 4.1 können nun Wörterbücher mit einem neuen Parameter gekennzeichnet werden, der besagt, dass die Einträge des Wörterbuchs nicht zur Zerlegung des Kompositums genutzt werden dürfen.
Ein Beispiel:
Die Abkürzung "Abk" könnte als Teil eines Kompositums identifiziert werden, etwa in dem Wort "Abklebeband", das nicht als Abkleben+Band, sondern als Abk+Leben+Band zerlegt werden würde.
Wenn das Abkürzungswörterbuch so gekennzeichnet ist, dass seine Einträge keine Kompositateile darstellen, kann das nicht mehr geschehen.
-26.6.2013-